
 Image by Teradata
Image by Teradata
In the previous installment of this series, we experimented with prompt engineering techniques to guide the responses of large language models (LLMs). We proposed building a trusted generative artificial intelligence (AI) system that enables business teams to talk to databases in plain English language. As we continue our generative AI exploration, we understand that responsibly building such system presents a unique set of challenges.
These challenges stem from the limitations of the LLMs, such as:
- Their token limits for responses and completions
- Their tendency to generate outputs based on nonexistent data (hallucinations)
- Their unfamiliarity with certain types of standard query language (SQL) syntax
For instance, Teradata VantageCloud has specialized SQL syntax and advanced functions that simplify large-scale data processing. The good news is that we can address these challenges by applying prompt engineering techniques introduced in Part 1 of this series.
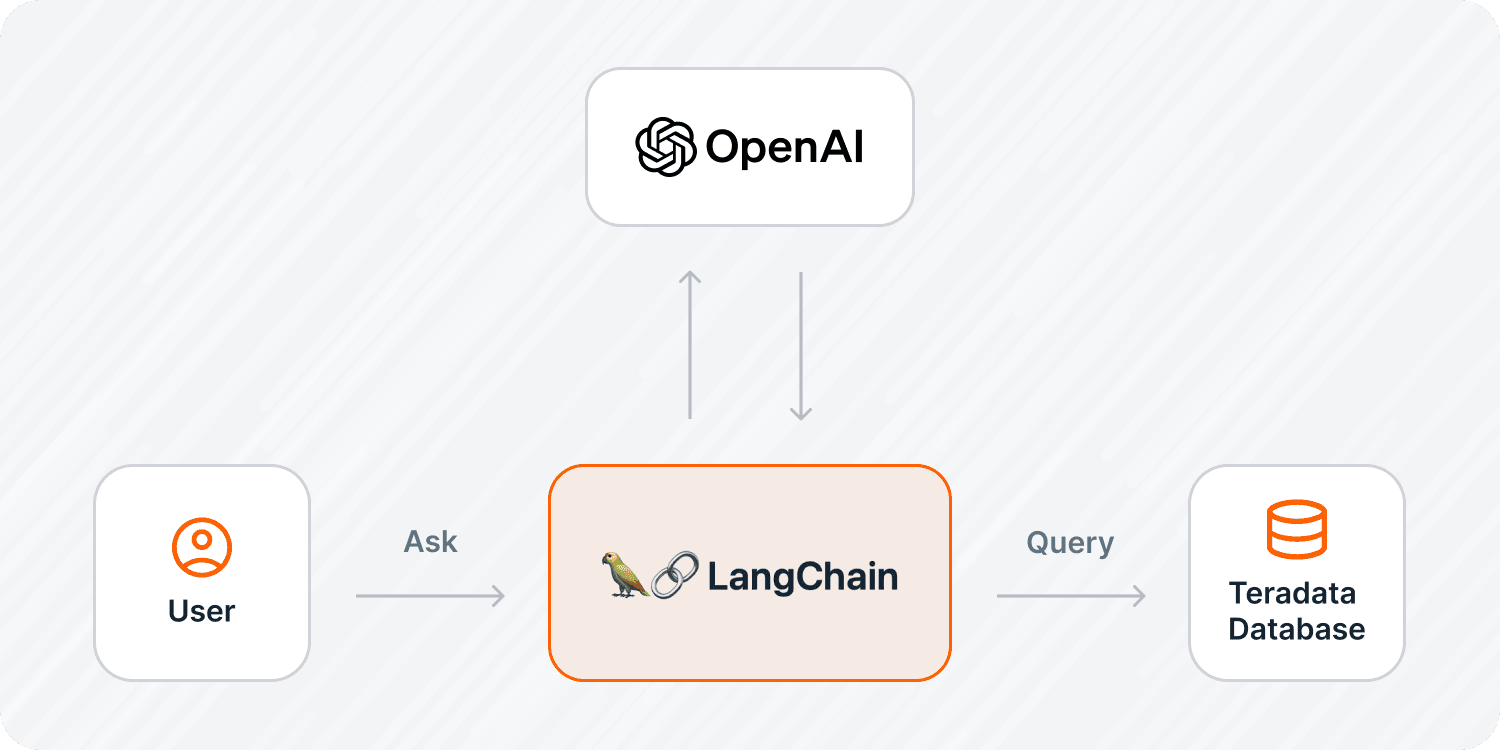
In this tutorial, we'll take those techniques a step further to create a question-and-answer generative AI system. We'll demonstrate how you can effortlessly translate your English queries into SQL and receive responses from your analytic database in plain English, as shown in the image below.

SQLDatabaseChain running on Jupyter Notebook
But how exactly do we achieve this, especially when dealing with petabytes of data that exceed the LLM token limits? The strategy involves providing the LLMs with precise instructions and information through prompt engineering. To help us make this a clean and efficient process, we leverage LangChain’s PromptTemplates and SQLDatabaseChain module classes to interact with LLMs.
Note: These solutions can be applied to all Teradata Vantage™ deployments and editions.
Tools for this tutorial:
- VantageCloud. We provision a free environment on VantageCloud at ClearScape Analytics™ Experience. Here, we’ll be able to explore VantageCloud, run our code in a Jupyter Notebook environment, and access data. ClearScape Analytics Experience is a fully featured environment for education and testing purposes only. For production data, request access to our production-grade editions, VantageCloud Enterprise and VantageCloud Lake.
- LangChain. LangChain is an open-source framework that makes it easy for developers to build context-aware applications. LangChain features SQL Chains and SQL Agents to build and run SQL queries based on natural language prompts (NLPs). In this tutorial, we leverage SQL Chains.
- OpenAI. The LLM we use for demonstration purposes is OpenAI’s GPT-3.5 turbo-instruct model, but the same principles can be applied to other LLMs that can generate human-like text responses, including GPT-3, GPT-3.5, GPT-4, Hugging Face BLOOM, Llama, and Google's FLAN-T5. The execution of this demonstration with OpenAI costs under $1.
Business context
We use a marketing campaign dataset with records for 11,000 customers, provided in the following steps. Each record consists of 22 data points for each person, including age, job, marital status, location, and income. These variables contribute to a final column that indicates whether a customer is likely to make a purchase, marked as “yes” or “no” under the “purchased” column. A marketing team uses a table like this to reduce marketing resources by identifying customers who would purchase the product and direct marketing efforts to them.
For this demonstration, we use this dataset to ask questions in English, have our LLM generate Teradata-style SQL based on our dataset’s schema, and return a response in plain English.

Marketing campaign dataset with 11,000 records
Based on this data set, here are some questions users can ask with our question-and-answer system:
- How many married customers have purchased the product?
- What is the number of purchases made by customers who are in management professions?
- What is the average number of days between a customer's last contact and their next purchase?
- What is the most effective communication method for reaching customers who have not purchased from our company in the past six months?
Let’s get started!
Creating a free ClearScape Analytics Experience environment
Create a free account or sign in.
ClearScape Analytics Experience landing page
Once you have signed in, select Create Environment to provision a new environment.
Name your environment and create a password.
Creating a ClearScape Analytics Experience environment
Select your region and select Create to initialize the environment.
Running the environment using Jupyter Notebook
Select Run Demos Using Jupyter to open the Demo.index tab.
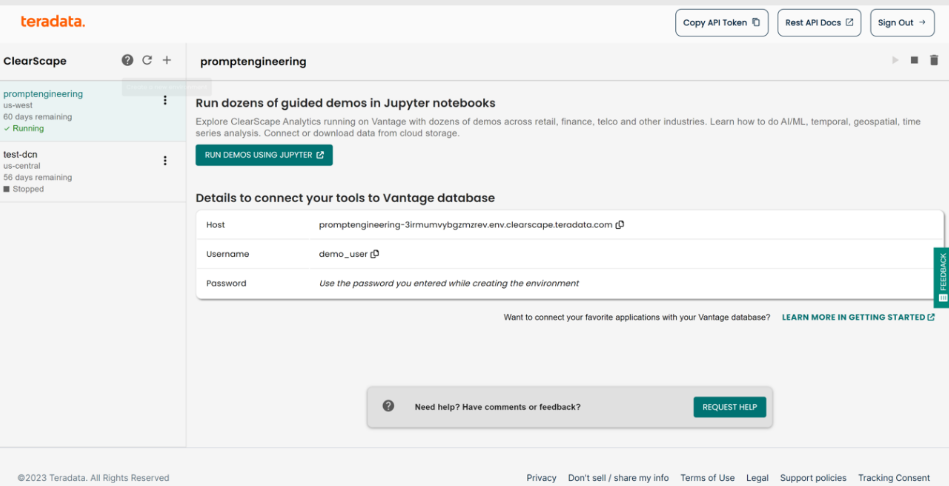
New ClearScape Analytics Experience environment
Navigate to the UseCases/Generative_Question_Answering_Python.ipynb file.
Generative_Question_Answering_Python.ipynb Jupyter Notebook introduction
This notebook requires some additional packages noted in the requirements.txt file. These packages are installed when we execute the first cell in our Generative_Question_Answering_Python.ipynb notebook.
Requirements.txt
langchain==0.0.335
openai==0.28.1
langchain-experimental==0.0.40
Configuring the environment
Once you open the Generative_Question_Answering_Python.ipynb, scroll down and run the first four code cell blocks by selecting the cells and pressing Shift+Enter to import the different client libraries and establish a connection to VantageCloud.
%%capture
# '%%capture' suppresses the display of installation steps of the following packages
!pip install -r requirements.txt --quiet
Here we import the Python packages we need for the demonstration. Note we import a library called teradataml. This package allows us to execute data management and analytic operations directly in the massively parallel architecture of VantageCloud. It eliminates the need for costly data movement and allows for easy access to built-in data management, exploration, and advanced analytic functions.
import io
import os
import numpy as np
import pandas as pd
# teradata lib
from teradataml import *
# LLM
import sqlalchemy
from sqlalchemy import create_engine
from langchain import PromptTemplate, SQLDatabase, LLMChain
from langchain_experimental.sql import SQLDatabaseChain
# Suppress warnings
warnings.filterwarnings("ignore")
display.max_rows = 5
You need an OpenAI application programming interface (API) key. If you don’t have one, refer to the instructions provided in our guide to get your OpenAI API key. Navigate to UseCases/Openai_setup_api_key/Openai_setup_api_key.md.
# enter your openai api key
api_key = input(prompt="\n Please Enter OpenAI API key: ")
Enter the password you set for your environment.
%run -i ../startup.ipynb
eng = create_context(host = 'host.docker.internal', username='demo_user', password = password)
print(eng)
Loading data for the demo on VantageCloud
When working with VantageCloud for data analysis, you have two options:
- Analyze data stored externally in object storage. This method uses native object storage integration to create ‘foreign tables‘ inside the database; point this virtual table to an external object storage location like Google Cloud, Azure Blob, and S3; and use SQL to analyze the data. The advantage here is that it minimizes data transfer and allows you to work within VantageCloud using foreign tables, without needing additional storage in your VantageCloud environment.
- Download data into your local VantageCloud environment. Alternatively, you can use native object storage integration to ingest data at scale into VantageCloud using one SQL request. Downloading data can result in faster execution of some steps that perform the initial access to the source data.
The demonstration defaults to downloading the data onto your local environment. You can switch modes by changing the comment in the string.
# %run -i ../run_procedure.py "call get_data('DEMO_MarketingCamp_cloud');" # Takes 20 seconds
%run -i ../run_procedure.py "call get_data('DEMO_MarketingCamp_local');" # Takes 20 seconds
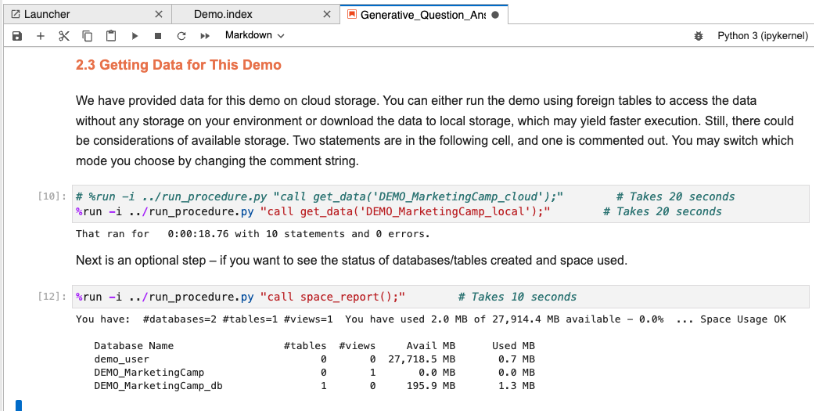
space_report() function displaying usage and available storage
We’ve simplified the process to access data for this demonstration, but behind the scenes, a stored procedure is performing the operations to create databases and tables and load the data.
*Here's a simplified code example for creating a foreign table. You'd need to ensure you have a database named DEMO_MarketingCamp created beforehand. Note: This is for demonstration only; you don't need to execute this code.
CREATE FOREIGN TABLE DEMO_MarketingCamp.Retail_Marketing
USING (
location('/gs/storage.googleapis.com/clearscape_analytics_demo_data/DEMO_MarketingCamp/Retail_Marketing/')
);
After you load the data onto your local storage in your VantageCloud environment, proceed to create a DataFrame. Here, we use the teradataml package to create an object that behaves just like a regular DataFrame but represents the data within VantageCloud. This enables us to operate on the data without having to copy it to the client, allowing for analysis and management of data at any scale.
tdf = DataFrame(in_schema("DEMO_MarketingCamp", "Retail_Marketing"))
print("Data information: \n", tdf.shape)
tdf.sort("customer_id")

Preview of the Retail_Marketing table with 11K records and 23 columns
The dataset consists of 11,162 records with 23 variables.
Connect to Teradata VantageCloud databases using SQLAlchemy
We now use LangChain to connect to our database and create a data catalog. This catalog allows LangChain to guide the LLM in identifying relevant databases and tables for generating SQL queries.
# Create the vantage SQLAlchemy engine
db_vantage = SQLDatabase(eng)
database = "DEMO_MarketingCamp"
def get_db_schema():
table_dicts = []
database_schema_dict = {
"database_name": database,
"table_name": "Retail_Marketing",
"column_names": tdf.columns,
}
table_dicts.append(database_schema_dict)
database_schema_string = "\n".join(
[
f"Database: {table['database_name']}\nTable: {table['table_name']}\nColumns: {', '.join(table['column_names'])}"
for table in table_dicts
]
)
return database_schema_string
Print the data catalog to view the schema that LangChain sends to the LLM.
database_schema = get_db_schema()
print(database_schema)
The output will be the following:
Database: DEMO_MarketingCamp
Table: Retail_Marketing
Columns: customer_id, age, profession, marital, education, city, monthly_income_in_thousand, family_members, communication_type, last_contact_day, last_contact_month, credit_card, num_of_cars, last_contact_duration, campaign, days_from_last_contact, prev_contacts_performed, payment_method, purchase_frequency, prev_campaign_outcome, gender, recency, purchased
This data catalog is then passed into our prompt, enabling our LLM to create accurate SQL queries based on the existing schema.
* This example uses one database and one table. To include additional databases and tables, append another dictionary to the table_dicts list to represent the new table and specify the database it belongs to. Also ensure that you have the columns of any tables available in a DataFrame like tdf. You can leverage native object storage integration to quickly ingest data from object storage, and then create a teradataml DataFrame from the foreign table as shown above. Though there are other ways to retrieve the column names of tables, in this scenario, the above is the most straightforward.
Prepare response and error display functions
Next, create the function that returns the result to the query in HTML-formatted text in our Jupyter Notebook environment. This can be accomplished by importing the display and markdown IPython modules.
from IPython.display import display, Markdown
def response_template(query, response):
if "result" in response:
return f"<p style = 'font-size:16px;font-family:Arial;color:#00233C'>SQL and response from user query {query} <br> <b>{response['result']}<b>"
else:
return f"<p style = 'font-size:16px;font-family:Arial;color:#00233C'>SQL and response from user query {query} <br> <b>{response}<b>"
def error_template():
return f"<p style = 'font-size:16px;font-family:Arial;color:#00233C'>Sorry, there was an error while generating the SQL query. The GenAI may have made a mistake in the syntax of the query. <br>"
Define LLM model
We import the OpenAI LLM object constructor from the LangChain llms that enables our application to seamlessly interact with OpenAI LLMs.
To initiate the LangChain LLM class for OpenAI, we set the temperature parameter, which can range from 0.0 to 1.0. For this specific application, set the temperature to 0 to ensure that the responses closely follow the prompt instructions and reduce the chance of made-up data and, as a result, made-up queries. This precision is desirable when querying data.
You can also pass in a model parameter to designate which specific OpenAI model you want to use. You can test the performance of different models by swapping out the specific model's name.
You also uncomment the LangChain variables if you want to use the LangSmith Tracing functionalities to log and view executions of your LLM application.
from langchain.llms import OpenAI
# OpenAI API
os.environ["OPENAI_API_KEY"] = api_key
# call open AI model - api
llm = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct")
##If you are using tracing via LangSmith, set these variables:
#os.environ["LANGCHAIN_API_KEY"] = ""
#os.environ["LANGCHAIN_ENDPOINT"]= "https://api.smith.langchain.com/"
#os.environ["LANGCHAIN_TRACING_V2"] = "true"
#os.environ["LANGCHAIN_PROJECT"] = "" #optional
Prompt engineering with LangChain
LLMs like OpenAI’s have been trained on massive datasets; therefore, they are fairly good at writing SQL. However, as mentioned previously, they have limitations. For example, they can make up tables and fields or generate SQL that is not aligned with specific database dialects. For example, while Teradata is an American National Standards Institute (ANSI) SQL dialect, it has unique syntax and functions that an LLM might not understand. To ground our LLM, we leverage LangChain’s promptTemplates class and SQLDatabaseChain to generate the appropriate instructions for our LLM.
We create a prompt and apply the prompt engineering elements and techniques from the first part of this series. For the best results, our prompt includes an accurate database description (our data catalog), along with task instructions, context, few-shot examples, and output instructions.
Run the following code:
# define a function that infers the database/table and sets the database for querying
def run_query(query):
prompt_template_query = (
"""Given an input question, first create a syntactically correct Teradata-style query to run, then look at the results of the query and return the answer.
Display SQLResult after the query is run in simple English statement.
Only use the following database schema: \n
"""
+ database_schema
+ """
Do not use below restricted words in SQL query:
1. LIMIT
2. FETCH
3. FIRST
Do not use 'count' or 'COUNT' as alias keyword instead use count_
Do not use 'LIMIT' or 'FETCH' keyword in the SQLQuery, instead use TOP keyword
To select top 3 results, use TOP keyword instead of LIMIT or FETCH.
Examples of question and expected SQLQuery
Question: Which city has the highest average income?
SQLQuery: SELECT TOP 1 city, AVG(monthly_income_in_thousand) AS avg_income
FROM DEMO_MarketingCamp.Retail_Marketing
WHERE monthly_income_in_thousand IS NOT NULL
GROUP BY city
ORDER BY avg_income DESC;
Question: count total number of records in table?
SQLQuery: SELECT count(*) as total_count FROM DEMO_MarketingCamp.Retail_Marketing
Write a Teradata SQL query for Question: {input}"""
)
PROMPT_sql = PromptTemplate(
input_variables=["input"], template=prompt_template_query
)
db_chain = SQLDatabaseChain.from_llm(
llm,
db_vantage,
prompt=PROMPT_sql,
verbose=True,
return_intermediate_steps=False,
use_query_checker=True,
)
response = db_chain(query)
return response
Our prompt is designed to guide the LLM through translating natural language questions into executable Teradata-style SQL queries. Let's analyze and identify the elements and techniques that contribute to our prompt's effectiveness.
Prompt elements:
- Instruction. “Given an input question, first create a syntactically correct Teradata-style query to run, then look at the results of the query and return the answer." This is the main instruction that guides the LLM on the task that it needs to perform.
- Context. We provide additional context to the LLM on the database schema by appending the database_schema string, noting specific restrictions on SQL query generation, and including additional rules. For example, while other SQL dialects might use FIRST n, LIMIT n, Teradata extension to ANSI SQL uses TOP n. For additional Teradata SQL Manipulation rules please refer to this document.
- Output instructions. We tell the LLM to return SQL results in simple, understandable English statements.
- Few-shot prompting. We include two examples of questions and their Teradata-style SQL queries to help the LLM understand the format and structure of the expected response.
- Input. The specific user questions replace the
{input}parameter in the template, at the end of the prompt. This allows the prompt template to become a versatile tool capable of handling a wide range of queries.
Now you are ready to run LangChain’s database chain to translate your English question to SQL and get the results from your database. Give it a spin in the following cell with a relevant question.
Test the function
try:
# Enter the query
query = """How many married customers have purchased the product?"""
# Response from Langchain
response = run_query(query)
display(Markdown(response_template(query, response)))
except:
display(Markdown(error_template()))
Output:

The notebook provides additional queries you can test against the QnA system, or you can come up with your own.
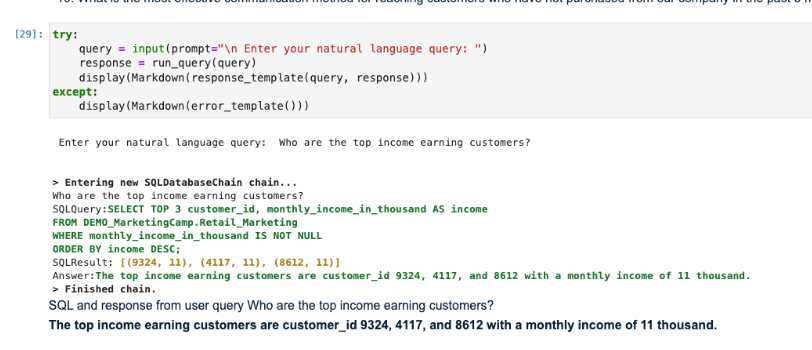
Who are the top earning customers?
Try asking questions in a different language other than English. Here we see a question in Spanish.

Cuantos clientes casados han comprado el producto?
Explore removing or adding instructions to the prompt to evaluate the responses.
If you would like to refine and optimize your QnA generative AI application, consider leveraging LangSmith.
Inspecting and debugging chains with LangSmith:
LangSmith is LangChain’s convenient and comprehensive software-as-a-service (SaaS) platform for logging and viewing runs of your LLM applications. With LangSmith, you can inspect the prompt and completion for every step of the chain, the total number of tokens used, and any errors to help debug your chains giving you a deeper understanding of how your queries are processed and how to improve them.
I’ve generated a public view of this execution in LangSmith that you can explore. The screen capture of LangSmith below offers an in-depth view of the operational details for each run within the chain, helping us understand how the final output was produced.
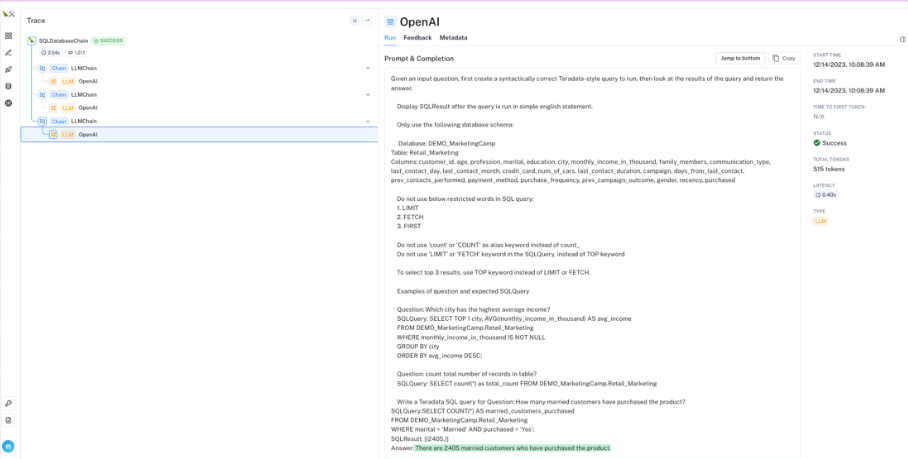
LangSmith Trace panel displaying SQLDatabaseChain logs
Note how in the “Trace” panel, this run took 2.04 seconds, 1,217 tokens total, three steps in the chain, and three calls to our OpenAI LLM.
To log your application’s executions and send that information to LangSmith, you can sign up for a LangSmith account and return to the step where you define the LLM model above. Include the following variables and your LangChain API key:
os.environ["LANGCHAIN_API_KEY"] = ""
os.environ["LANGCHAIN_ENDPOINT"]= "https://api.smith.langchain.com/"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
Conclusion
Thank you for completing this tutorial. We’ve developed a basic question-and-answer system capable of querying VantageCloud databases. In our next installment of this series, we’ll explore enhancing our system with the ability to handle more complex questions using powerful in-database analytic functions.
Teradata is the trusted AI company, and Teradata VantageCloud is the most complete cloud analytics and data platform for AI, offering more than 150 in-database functions. These functions simplify data exploration, feature engineering, model training, path analysis, and more. When these functions are executed, they operate directly within the database, eliminating the need to set up separate environments.